两个工具
dir
dir(包/类)
查看包中的类或类中的函数help
help(函数/类)查看函数的说明文档
pytorch加载数据
创建myData类继承Dataset,重写__init__,__getitem__,__len__方法
An abstract class representing a
Dataset.All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite
__getitem__(), supporting fetching a data sample for a given key. Subclasses could also optionally overwrite__len__(), which is expected to return the size of the dataset by manySamplerimplementations and the default options ofDataLoader.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30from torch.utils.data import Dataset
import os
from PIL import Image
class myData(Dataset):
def __init__(self,root_dir,label_dri):
self.root_dir = root_dir
self.label_dir = label_dri
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
ants_label_dir = r'ants'
bees_label_dir = r'bees'
root_dir = r'D:\learn_pythorch\dataset\train'
ants_data = myData(root_dir,ants_label_dir)
bees_data = myData(root_dir,bees_label_dir)
TensorBoard的使用
1 | |
–logdir指定使用的log文件夹
–port指定端口
add_scalar
add_image
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46def add_image(
self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"
):
"""Add image data to summary.
Note that this requires the ``pillow`` package.
Args:
tag (string): Data identifier
img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
seconds after epoch of event
dataformats (string): Image data format specification of the form
CHW, HWC, HW, WH, etc.
Shape:
img_tensor: Default is :math:`(3, H, W)`. You can use ``torchvision.utils.make_grid()`` to
convert a batch of tensor into 3xHxW format or call ``add_images`` and let us do the job.
Tensor with :math:`(1, H, W)`, :math:`(H, W)`, :math:`(H, W, 3)` is also suitable as long as
corresponding ``dataformats`` argument is passed, e.g. ``CHW``, ``HWC``, ``HW``.
Examples::
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
writer.add_image('my_image', img, 0)
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC')
writer.close()
Expected result:
.. image:: _static/img/tensorboard/add_image.png
:scale: 50 %
"""img_tensor的类型为Tensor,numpy,可以用opencv打开图片,如果用PIL打开的图片要用np.array(img)转换为np类型。
dataformats要根据图片的shape决定。
1 | |
transforms
ToTensor
将PIL或numpy类型的图片转换为tensor类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = 'D:\\learn_pythorch\\dataset\\train\\ants\\0013035.jpg'
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer = SummaryWriter('logs')
writer.add_image('Tensor_img',tensor_img)
writer.close()
print(tensor_img)Resize()改变图片大小
Normalize()正则化
RandomCrop()随机裁剪指定大小的图片
```python
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = ‘D:\learn_pythorch\dataset\train\ants\0013035.jpg’
writer = SummaryWriter(‘logs’)
img = Image.open(img_path)trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image(‘ToTensor’,img_tensor)Normalize()正则化
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,3,5],[7,9,2])
img_norm = trans_norm(img_tensor)
print(img_tensor[0][0][0])
writer.add_image(‘Normalize’,img_norm)Resize()改变图片大小
print(img.size)
trans_resize = transforms.Resize((360,480))
img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
writer.add_image(‘Resize’,img_resize,0)
print(img_resize)trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image(‘Resize’,img_resize_2,1)RandomCrop()随机裁剪指定大小的图片
trans_random = transforms.RandomCrop((300,400))
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):img_crop = trans_compose_2(img) writer.add_image('RandomCrop',img_crop,i)writer.close()
1
2
3
4
5
6
7
8
9
10
11
- 采用transforms.Compose(),将一系列的transforms有序组合,实现时按照这些方法依次对图像操作。
```python
train_transform = transforms.Compose([
transforms.Resize((32, 32)), # 缩放
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.ToTensor(), # 图片转张量,同时归一化0-255 ---》 0-1
transforms.Normalize(norm_mean, norm_std), # 标准化均值为0标准差为1
])
数据集
1 | |
DataLoader
- dataset 指定数据集
- batch_size 指定batch_size
- shuffle 为True时随机选择时间,False不随机
- num_workers 报错时可设置为0
- drop_last 当数据集不能恰好分成n分时,为True丢弃剩余数据,False不丢弃
1 | |
神经网络
基本骨架nn.Module
input ==> forward ==> output
1 | |
卷积
1 | |
神经网络
神经网络–卷积层(torch.nn.conv)
其实就是对nn.function的进一步封装
如nn.Conv2(),最常用的是这五个参数:in_channels、 out_channels、kernel_size、stride、 padding
实例:
#在初始化方法中定义进行卷积操作
- self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
- in_channels=3:三通道输入(彩色图片)
- out_channels=6:输出是六通道(6层),即生成6个卷积核
- kernel_size=3:每个卷积核的维度是3*3
- stride=1:步长为1
- padding=0:
1 | |
池化层–最大池化(torch.nn.maxpool)
最大池化层(常用的是maxpool2d)的作用:
- 一是对卷积层所提取的信息做更一步降维,减少计算量
- 二是加强图像特征的不变性,使之增加图像的偏移、旋转等方面的鲁棒性
- 类似于观看视频时不同的清晰度,实际效果就像给图片打马赛克
maxpool2d:注意输入的图像形状为4维,即形状不对时要先reshape
实例及结果:
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
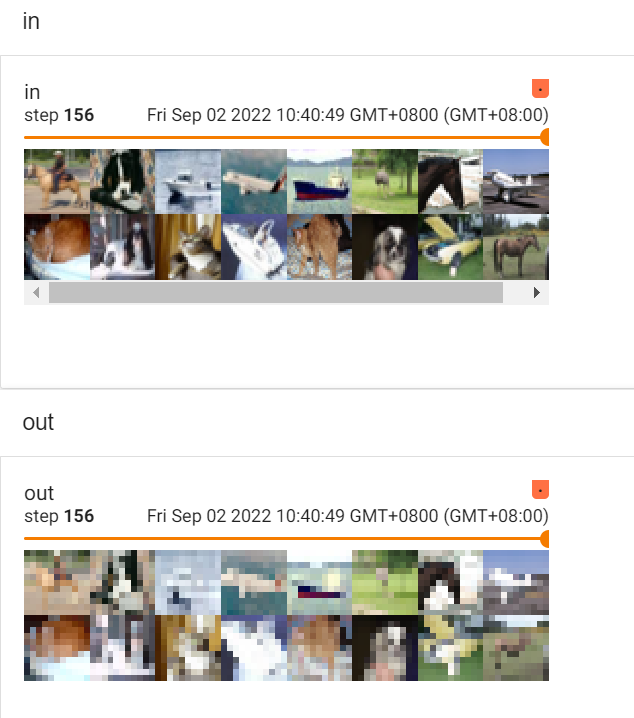
非线性激活(Non-linear Activations)
非线性变换的主要目的就是给网中加入一些非线性特征,非线性越多才能训练出符合各种特征的模型。常见的非线性激活:
ReLU:主要是对小于0的进行截断(将小于0的变为0),图像变换效果不明显
主要参数是inplace:
inplace为真时,将处理后的结果赋值给原来的参数;为假时,原值不会改变。
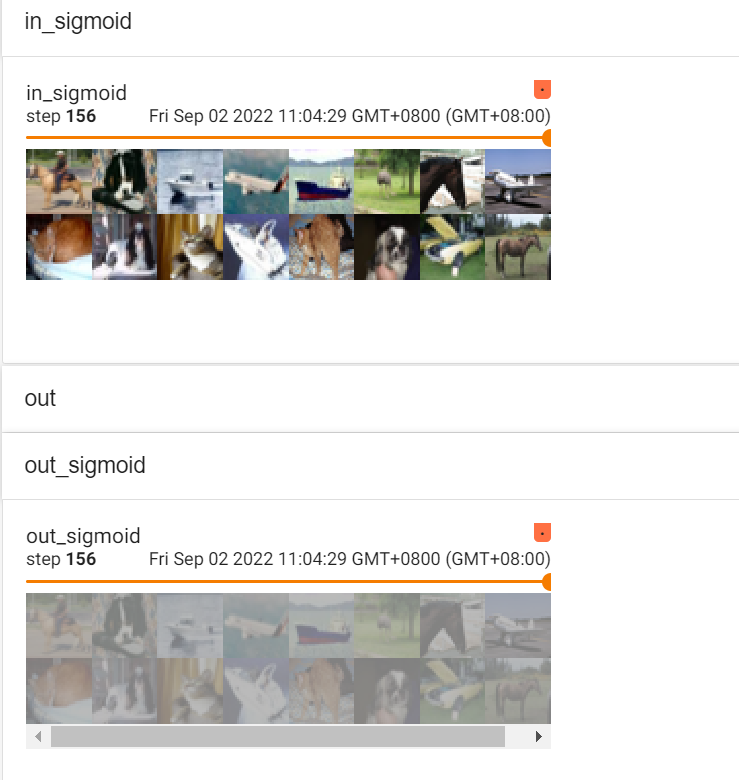
SIGMOID: 归一化处理
效果没有ReLU好,但对于多远分类问题,必须采用sigmoid
处理后结果
线性层(torch.nn.linear)
线性函数为:torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None),其中重要的3个参数in_features、out_features、bias说明如下:
in_features:每个输入(x)样本的特征的大小
out_features:每个输出(y)样本的特征的大小
bias:如果设置为False,则图层不会学习附加偏差。默认值是True,表示增加学习偏置。
作用可以是缩小一维的数据长度
1 | |
SEQUENTIAL的使用(torch.nn.Sequential)
可以方便编写代码,使代码更加简洁

使用tensorboard中的add_graph 查看神经网络的流程图
不使用sequential
1 | |
使用sequential
1 | |
Loss函数
L1Loss
mean absolute error (MAE)

1 | |
MSELoss
mean squared error

CrossEntropyLoss
交叉熵损失

优化器
1、过程描述
继上节的计算损失函数和反向传播,
之后便是根据损失值,利用优化器进行梯度更新,然后不断降低loss的过程
一般要对数据集扫描多遍,进行参数的多次更新,才能得到一个较好的效果。
注意,每次更新后要将梯度置0,然后重新计算梯度注意,每次更新后要将梯度置0,然后重新计算梯度
2、常用优化器:
优化器的种类比较多,常用的就是随机梯度下降(SGD) 等
不同的优化器的参数列表一般不同,但都会有 params(模型的参数列表)和lr(学习率)参数,
一般设置这两个参数,其他的可用默认值
1 | |
模型保存和加载
概述
因为有些较大的网络模型(无论是加载初始参数还是预训练过的参数)都需要花费一定的时间,特别是预训练的模型,要花很长时间下载参数,
所以我们可以将反复用到的模型保存下来,到时候直接读取使用即可
保存和读取方法
一般训练好的模型都需要进行保存,否则每次使用都要重新训练。
方式一
- 保存:保存模型结构及其参数。torch.save(model, path)
- 读取:获取一个完整的模型。torch.load(“模型名”)
方式二
保存:只保存模型的参数。torch.save(model.state_dict(), path)
读取:只能加载出模型的参数,要先新建网络模型,然后再装载参数(一般用于加载预训练的参数)。
陷阱:自定义的网络如果保存后再加载的话,需要再重新定义一遍网络结构。
1 | |
1 | |
完整训练流程
1 | |
使用GPU训练
方法一:cuda
在网络模型、数据集、Loss加上cuda即可
1 | |
方法二:to(device)
1 | |
1 | |

a-c-dream
贵在坚持