GOPATH设置
1 | |
路径写工作目录即可,多个目录用冒号分隔
以上 $GOPATH 目录约定有三个子目录:
- src 存放源代码(比如:.go .c .h .s 等)
- pkg 编译后生成的文件(比如:.a)
- bin 编译后生成的可执行文件(为了方便,可以把此目录加入到 $PATH 变量中,如果有多个 gopath,那么使用
${GOPATH//://bin:}/bin添加所有的 bin 目录)
Go 命令
go build
这个命令主要用于编译代码。在包的编译过程中,若有必要,会同时编译与之相关联的包。
如果是普通包,当你执行
go build之后,它不会产生任何文件。如果你需要在$GOPATH/pkg下生成相应的文件,那就得执行go install。如果是
main包,当你执行go build之后,它就会在当前目录下生成一个可执行文件。如果你需要在$GOPATH/bin下生成相应的文件,需要执行go install,或者使用go build -o 路径/a.exe。如果某个项目文件夹下有多个文件,而你只想编译某个文件,就可在
go build之后加上文件名,例如go build a.go;go build命令默认会编译当前目录下的所有 go 文件。你也可以指定编译输出的文件名。我们可以指定
go build -o astaxie.exe,默认情况是你的 package 名 (非 main 包),或者是第一个源文件的文件名 (main 包)。go build 会忽略目录下以
_或.开头的 go 文件。如果你的源代码针对不同的操作系统需要不同的处理,那么你可以根据不同的操作系统后缀来命名文件。例如有一个读取数组的程序,它对于不同的操作系统可能有如下几个源文件:
array_linux.go
array_darwin.go
array_windows.go
array_freebsd.gogo build的时候会选择性地编译以系统名结尾的文件(Linux、Darwin、Windows、Freebsd)。例如 Linux 系统下面编译只会选择 array_linux.go 文件,其它系统命名后缀文件全部忽略。
go clean
这个命令是用来移除当前源码包和相关源码包里面编译生成的文件。这些文件包括
1 | |
go fmt
go 强制了代码格式(比如左大括号必须放在行尾)
不按照此格式的代码将不能编译通过,为了减少浪费在排版上的时间,go 工具集中提供了一个 go fmt 命令它可以帮你格式化你写好的代码文件,使你写代码的时候不需要关心格式,你只需要在写完之后执行 go fmt <文件名>.go,你的代码就被修改成了标准格式
使用 go fmt 命令,其实是调用了 gofmt,而且需要参数 -w,否则格式化结果不会写入文件。gofmt -w -l src,可以格式化整个项目。
参数:
-l显示那些需要格式化的文件-w把改写后的内容直接写入到文件中,而不是作为结果打印到标准输出。
go get
这个命令是用来动态获取远程代码包的,目前支持的有 BitBucket、GitHub、Google Code 和 Launchpad。这个命令在内部实际上分成了两步操作:第一步是下载源码包,第二步是执行 go install。
go install
这个命令在内部实际上分成了两步操作:第一步是生成结果文件 (可执行文件或者 .a 包),第二步会把编译好的结果移到 $GOPATH/pkg 或者 $GOPATH/bin。
参数支持 go build 的编译参数。大家只要记住一个参数 -v 就好了,这个随时随地的可以查看底层的执行信息。
go test
执行这个命令,会自动读取源码目录下面名为 *_test.go 的文件,生成并运行测试用的可执行文件。
go tool
go generate
这个命令是从 Go1.4 开始才设计的,用于在编译前自动化生成某类代码。
godoc
在 Go1.2 版本之前还支持 go doc 命令,但是之后全部移到了 godoc 这个命令下,需要这样安装 go get golang.org/x/tools/cmd/godoc
其他命令
1 | |
Go 基本语法
首先我们要了解一个概念,Go 程序是通过 package 来组织的
package <pkgName>(在我们的例子中是 package main )这一行告诉我们当前文件属于哪个包,而包名 main 则告诉我们它是一个可独立运行的包,它在编译后会产生可执行文件。除了 main 包之外,其它的包最后都会生成 *.a 文件(也就是包文件)并放置在 $GOPATH/pkg/$GOOS_$GOARCH 中(以 Mac 为例就是 $GOPATH/pkg/darwin_amd64)。
1 | |
1 | |
变量定义
先定义再赋值
使用 var 关键字是 Go 最基本的定义变量方式,与 C 语言不同的是 Go 把变量类型放在变量名后面:
1 | |
直接赋值
现在是不是看上去非常简洁了?:= 这个符号直接取代了 var 和 type, 这种形式叫做简短声明。不过它有一个限制,那就是它只能用在函数内部;在函数外部使用则会无法编译通过,所以一般用 var 方式来定义全局变量。
1 | |
_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃。在这个例子中,我们将值 35 赋予 b,并同时丢弃 34:
1 | |
Go 对于已声明但未使用的变量会在编译阶段报错,比如下面的代码就会产生一个错误:声明了 i 但未使用。
1 | |
定义常量
所谓常量,也就是在程序编译阶段就确定下来的值,而程序在运行时无法改变该值。在 Go 程序中,常量可定义为数值、布尔值或字符串等类型。
它的语法如下:
1 | |
数组类型
1 | |
浮点数的类型有 float32 和 float64 两种(没有 float 类型),默认是 float64。
它的默认类型是 complex128(64 位实数 + 64 位虚数)。如果需要小一些的,也有 complex64 (32 位实数 + 32 位虚数)。复数的形式为 RE + IMi,其中 RE 是实数部分,IM 是虚数部分,而最后的 i 是虚数单位。下面是一个使用复数的例子:
1 | |
字符串
我们在上一节中讲过,Go 中的字符串都是采用 UTF-8 字符集编码。字符串是用一对双引号("")或反引号( )括起来定义,它的类型是 string。
在 Go 中字符串是不可变的
修改字符串代码:
1 | |
Go 中可以使用 + 操作符来连接两个字符串
字符串虽不能更改,但可进行切片操作
可以通过 ` 声明一个多行的字符串
错误类型
Go 内置有一个 error 类型,专门用来处理错误信息,Go 的 package 里面还专门有一个包 errors 来处理错误
Go 程序设计的一些规则
Go 之所以会那么简洁,是因为它有一些默认的行为:
- 大写字母开头的变量是可导出的,也就是其它包可以读取的,是公有变量;小写字母开头的就是不可导出的,是私有变量。
- 大写字母开头的函数也是一样,相当于
class中的带public关键词的公有函数;小写字母开头的就是有private关键词的私有函数。
array、slice、map
array
array 就是数组,它的定义方式如下:
1 | |
在 [n]type 中,n 表示数组的长度,type 表示存储元素的类型。对数组的操作和其它语言类似,都是通过 [] 来进行读取或赋值
1 | |
slice
在很多应用场景中,数组并不能满足我们的需求。在初始定义数组时,我们并不知道需要多大的数组,因此我们就需要 “动态数组”。在 Go 里面这种数据结构叫 slice
slice 并不是真正意义上的动态数组,而是一个引用类型。slice 总是指向一个底层 array,slice 的声明也可以像 array 一样,只是不需要长度。
1 | |
slice 可以从一个数组或一个已经存在的 slice 中再次声明。slice 通过 array[i:j] 来获取,其中 i 是数组的开始位置,j 是结束位置,但不包含 array[j],它的长度是 j-i。
1 | |
slice 有一些简便的操作
slice的默认开始位置是 0,ar[:n]等价于ar[0:n]slice的第二个序列默认是数组的长度,ar[n:]等价于ar[n:len(ar)]如果从一个数组里面直接获取
slice,可以这样ar[:],因为默认第一个序列是 0,第二个是数组的长度,即等价于ar[0:len(ar)]slice是引用类型,所以当引用改变其中元素的值时,其它的所有引用都会改变该值
对于 slice 有几个有用的内置函数:
len获取slice的长度cap获取slice的最大容量append向slice里面追加一个或者多个元素,然后返回一个和slice一样类型的slicecopy函数copy从源slice的src中复制元素到目标dst,并且返回复制的元素的个数
map
map 也就是 Python 中字典的概念,它的格式为 map[keyType]valueType
1 | |
map是无序的,每次打印出来的map都会不一样,它不能通过index获取,而必须通过key获取map的长度是不固定的,也就是和slice一样,也是一种引用类型- 内置的
len函数同样适用于map,返回map拥有的key的数量 map的值可以很方便的修改,通过numbers["one"]=11可以很容易的把 key 为one的字典值改为11
make、new操作
make 用于内建类型(map、slice 和 channel)的内存分配。new 用于各种类型的内存分配。
内建函数 new 本质上说跟其它语言中的同名函数功能一样:new(T) 分配了零值填充的 T 类型的内存空间,并且返回其地址,即一个 *T 类型的值。用 Go 的术语说,它返回了一个指针,指向新分配的类型 T 的零值。有一点非常重要:
new 返回指针。
内建函数 make(T, args) 与 new(T) 有着不同的功能,make 只能创建 slice、map 和 channel,并且返回一个有初始值 (非零) 的 T 类型,而不是 *T。本质来讲,导致这三个类型有所不同的原因是指向数据结构的引用在使用前必须被初始化。
make 返回初始化后的(非零)值。
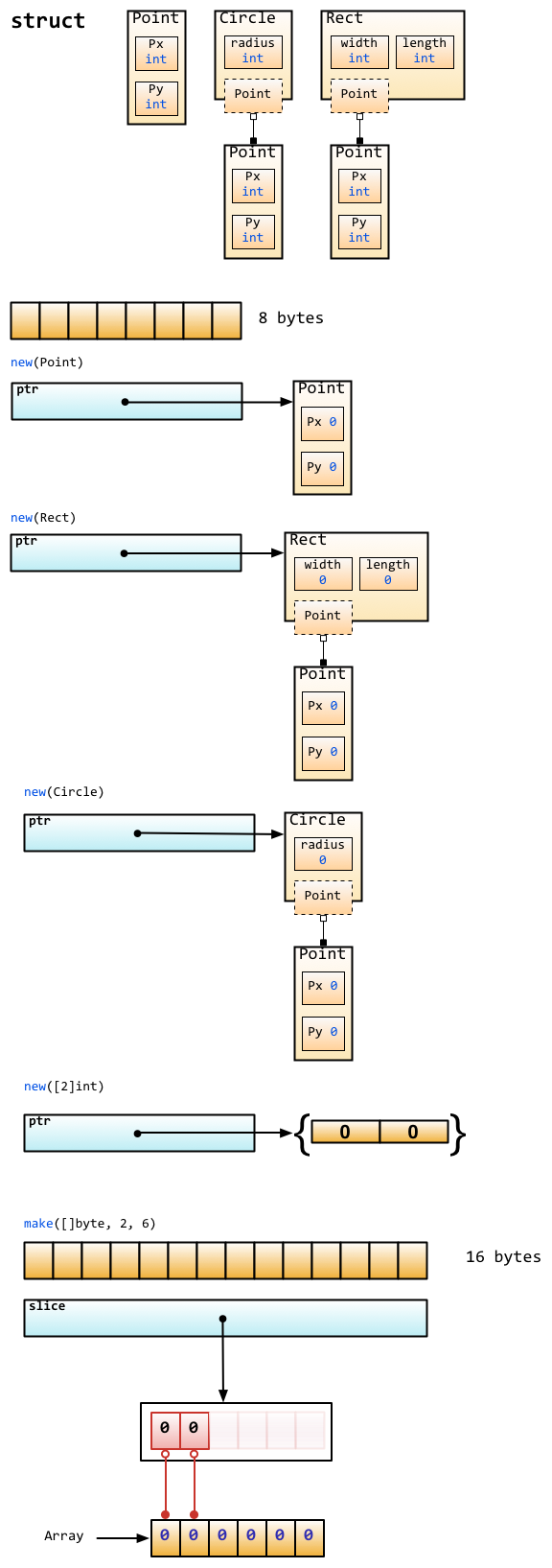
零值
1 | |
struct
struct 声明
1 | |
struct 的匿名字段
我们上面介绍了如何定义一个 struct,定义的时候是字段名与其类型一一对应,实际上 Go 支持只提供类型,而不写字段名的方式,也就是匿名字段,也称为嵌入字段。
当匿名字段是一个 struct 的时候,那么这个 struct 所拥有的全部字段都被隐式地引入了当前定义的这个 struct。
1 | |
struct 不仅仅能够将 struct 作为匿名字段,自定义类型、内置类型都可以作为匿名字段,而且可以在相应的字段上面进行函数操作
面向对象
method
- 虽然 method 的名字一模一样,但是如果接收者不一样,那么 method 就不一样
- method 里面可以访问接收者的字段
- 调用 method 通过
.访问,就像 struct 里面访问字段一样
1 | |
method 继承
method 也是可以继承的。如果匿名字段实现了一个 method,那么包含这个匿名字段的 struct 也能调用该 method。
1 | |
method重写
上面的例子中,如果 Employee 想要实现自己的 SayHi, 怎么办?简单,和匿名字段冲突一样的道理,我们可以在 Employee 上面定义一个 method,重写了匿名字段的方法。请看下面的例子
1 | |
并发
goroutine 是 Go 并行设计的核心。goroutine 说到底其实就是协程,但是它比线程更小,十几个 goroutine 可能体现在底层就是五六个线程,执行 goroutine 只需极少的栈内存 (大概是 4~5 KB),goroutine 比 thread 更易用、更高效、更轻便。
goroutine 是通过 Go 的 runtime 管理的一个线程管理器。goroutine 通过 go 关键字实现了,其实就是一个普通的函数。
1 | |
我们可以看到 go 关键字很方便的就实现了并发编程。
上面的多个 goroutine 运行在同一个进程里面,共享内存数据,不过设计上我们要遵循:不要通过共享来通信,而要通过通信来共享。
channels
goroutine 运行在相同的地址空间,因此访问共享内存必须做好同步。那么 goroutine 之间如何进行数据的通信呢,Go 提供了一个很好的通信机制 channel。channel 可以与 Unix shell 中的双向管道做类比:可以通过它发送或者接收值。这些值只能是特定的类型: channel 类型。定义一个 channel 时,也需要定义发送到 channel 的值的类型。注意,必须使用 make 创建 channel:
channel 通过操作符 <- 来接收和发送数据
1 | |
函数定义


a-c-dream
贵在坚持
109
13
0