定时任务CronJob
1 | |
1 | |
初始化容器 InitContainer
污点和容忍
污点:是标注在节点上的,当我们在一个节点上打上污点以后,k8s 会认为尽量不要将 pod 调度到该节点上,除非该 pod 上面表示可以容忍该污点,且一个节点可以打多个污点,此时则需要 pod 容忍所有污点才会被调度该节点。
污点的效果:
- NoSchedule:如果不能容忍该污点,那么 Pod 就无法调度到该节点上
- NoExecute:如果 Pod 不能忍受这类污点,Pod 会马上被驱逐。
容忍:是标注在 pod 上的,当 pod 被调度时,如果没有配置容忍,则该 pod 不会被调度到有污点的节点上,只有该 pod 上标注了满足某个节点的所有污点,则会被调度到这些节点
容忍有两种:
- Equal:比较操作类型为 Equal,则意味着必须与污点值做匹配,key/value都必须相同,才表示能够容忍该污点
- Exists:容忍与污点的比较只比较 key,不比较 value,不关心 value 是什么东西,只要 key 存在,就表示可以容忍。
污点实例:
查看现在运行的pod

使用kubectl taint no k8s-node2 memory=low:NoSchedule命令给node2打上污点,效果为NoSchedule
使用describe查看node2上的污点
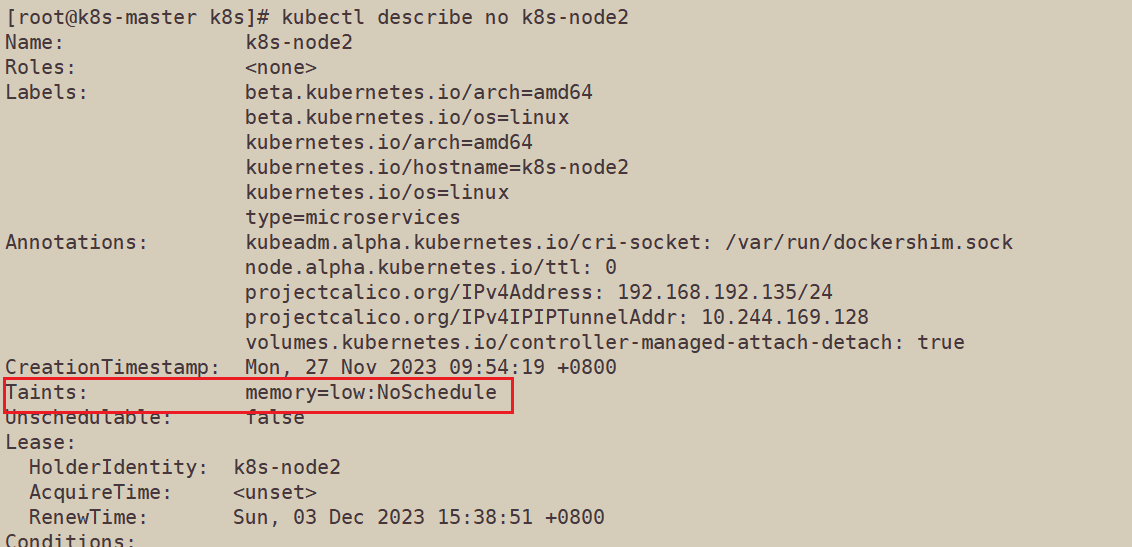
再次查看运行的pod,发现在打污点之前就已经在node2上运行的pod会继续在node2上运行。说明NoSchedule不会驱逐已经运行的pod,后面再分配任务时,不能容忍该污点的pod就不会被分配到该节点上运行。

查看master,发现master节点上默认被打上了污点
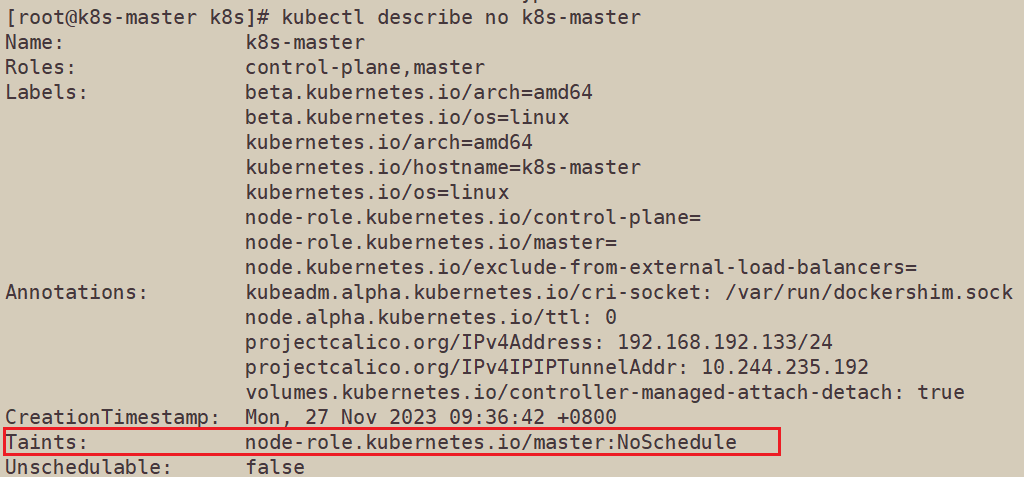
使用kubectl taint no k8s-master node-role.kubernetes.io/master:NoSchedule-命令去掉master节点上的污点,然后创建新的pod。
查看pod发现,此时新的pod被分配到了master上

使用kubectl taint no k8s-master node-role.kubernetes.io/master:NoExecute命令给master打上污点
此时再查看pod,发现原来在master上运行的pod转移到node1上运行了
解释:
因为master上的污点的效果是NoExecute,所以会驱逐在master上运行的pod,而此时node2上又有NoSchedule污点,所以pod只能在node1上运行了。

容忍实例:
edit nginx-deploy 增加容忍配置
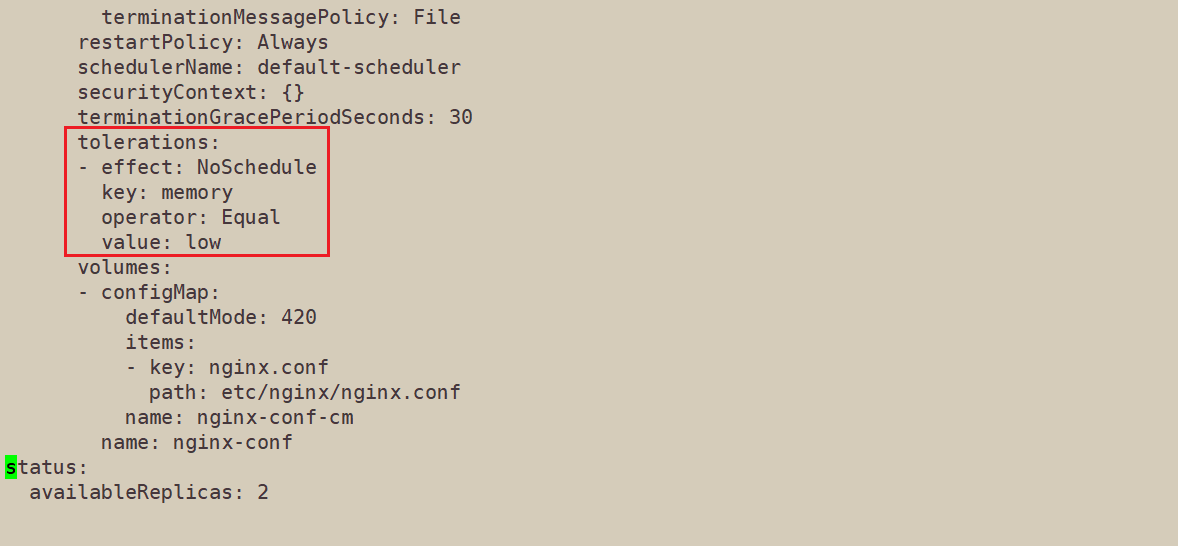
更改之后发现新创建的pod可以在node2上运行

下面使用Exists容忍,由于Exists容忍值匹配key,所以不用写value

更改之后,再次查看pod,发现仍然可以在node2上运行

将node2上的污点改为NoExecute,同时将nginx-deploy中的容忍也改为NoExecute
此时可以看到只有nginx-depoly的pod还在node2上运行

这里有一个参数,tolerationSeconds 属性,则可以一直运行,设置了 tolerationSeconds: 3600 属性,则该 pod 还能继续在该节点运行 3600 秒
我们为nginx-deploy设置tolerationSeconds:10
这样就可以看到运行在node2上的pod,10后就会调度一次,如果又调度到了node2上,10秒后会继续调度,反复如此。
最后我们取消node2上的污点
亲和性
亲和性与反亲和性
nodeSelector 提供了一种最简单的方法来将 Pod 约束到具有特定标签的节点上。 亲和性和反亲和性扩展了你可以定义的约束类型。使用亲和性与反亲和性的一些好处有:
- 亲和性、反亲和性语言的表达能力更强。
nodeSelector只能选择拥有所有指定标签的节点。 亲和性、反亲和性为你提供对选择逻辑的更强控制能力。 - 你可以标明某规则是“软需求”或者“偏好”,这样调度器在无法找到匹配节点时仍然调度该 Pod。
- 你可以使用节点上(或其他拓扑域中)运行的其他 Pod 的标签来实施调度约束, 而不是只能使用节点本身的标签。这个能力让你能够定义规则允许哪些 Pod 可以被放置在一起。
亲和性功能由两种类型的亲和性组成:
- 节点亲和性功能类似于
nodeSelector字段,但它的表达能力更强,并且允许你指定软规则。 - Pod 间亲和性/反亲和性允许你根据其他 Pod 的标签来约束 Pod。
节点亲和性
节点亲和性概念上类似于 nodeSelector, 它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于nodeSelector, 但其语法表达能力更强。preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
example
1 | |
| 操作符 | 行为 |
|---|---|
In |
标签值存在于提供的字符串集中 |
NotIn |
标签值不包含在提供的字符串集中 |
Exists |
对象上存在具有此键的标签 |
DoesNotExist |
对象上不存在具有此键的标签 |
Gt |
提供的值将被解析为整数,并且该整数小于通过解析此选择算符命名的标签的值所得到的整数 |
Lt |
提供的值将被解析为整数,并且该整数大于通过解析此选择算符命名的标签的值所得到的整数 |
解释一下配置文件,配置文件中 requiredDuringSchedulingIgnoredDuringExecution是必须满足的,也就是说必须是linux平台。preferredDuringSchedulingIgnoredDuringExecution是可选项,label-1=key-1的权重时1,label-2=key-2的权重是50。
下面进行label的配置
第一项linux平台,三个节点都满足

给node1打label-1,node2打label-2

删除当前pod,等待pod重新创建后,发现都在node2上
因为node1满足条件1(权重为1),node2满足条件2(权重为50),所以都去node2上面了。

下面将条件二改为NotIn
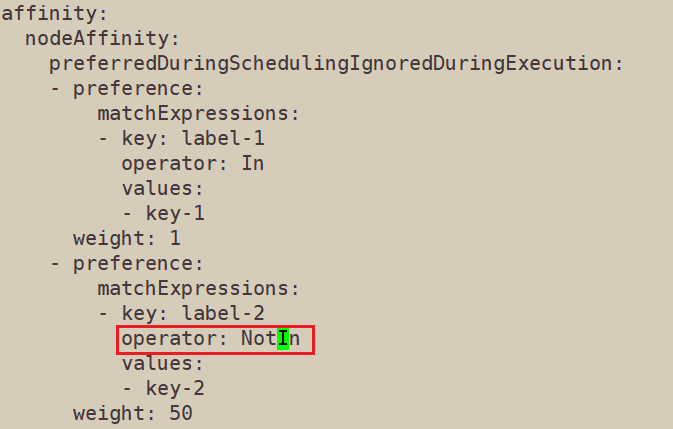
此时pod都分配到node1上了
因为node1满足条件1(权重为1),node2两个条件都不满足,所以都去node1上面了。
下面去掉master上的污点
kubectl taint no k8s-master node-role.kubernetes.io/master:NoSchedule-
然后删除pod,等待deploy自动重启pod

node1和master上各一个

a-c-dream
贵在坚持